The 10:1 Rule: Why Production Agentic Systems Spend More Tokens Validating Than Doing
Your agent spends 3–10x more tokens checking its work than doing it. That ratio sounds broken. It's actually the cheapest reliability you'll ever buy.
Most teams building AI agents obsess over the doing — tool calls, chain-of-thought reasoning, retrieval pipelines. They pour weeks into the action loop, demo it to leadership, get a standing ovation, and deploy to production. Then they spend the next six months firefighting.
I've watched this pattern repeat across enough teams to have a name for it: demo-driven development. And the thing it hides is this: in well-engineered production agentic systems, validation consumes 3–10x more tokens than execution. The majority of your LLM budget isn't doing work. It's checking work.
That's not a bug in the architecture. It's the architecture.

Why Naive Agent Loops Fail
The textbook agent loop looks elegant: observe → think → act → repeat. One model, one loop, a few tools. Ship it.
In a controlled demo with curated inputs, this works beautifully. In production, with real users who type things like "do the thing from last week but different," it falls apart fast.
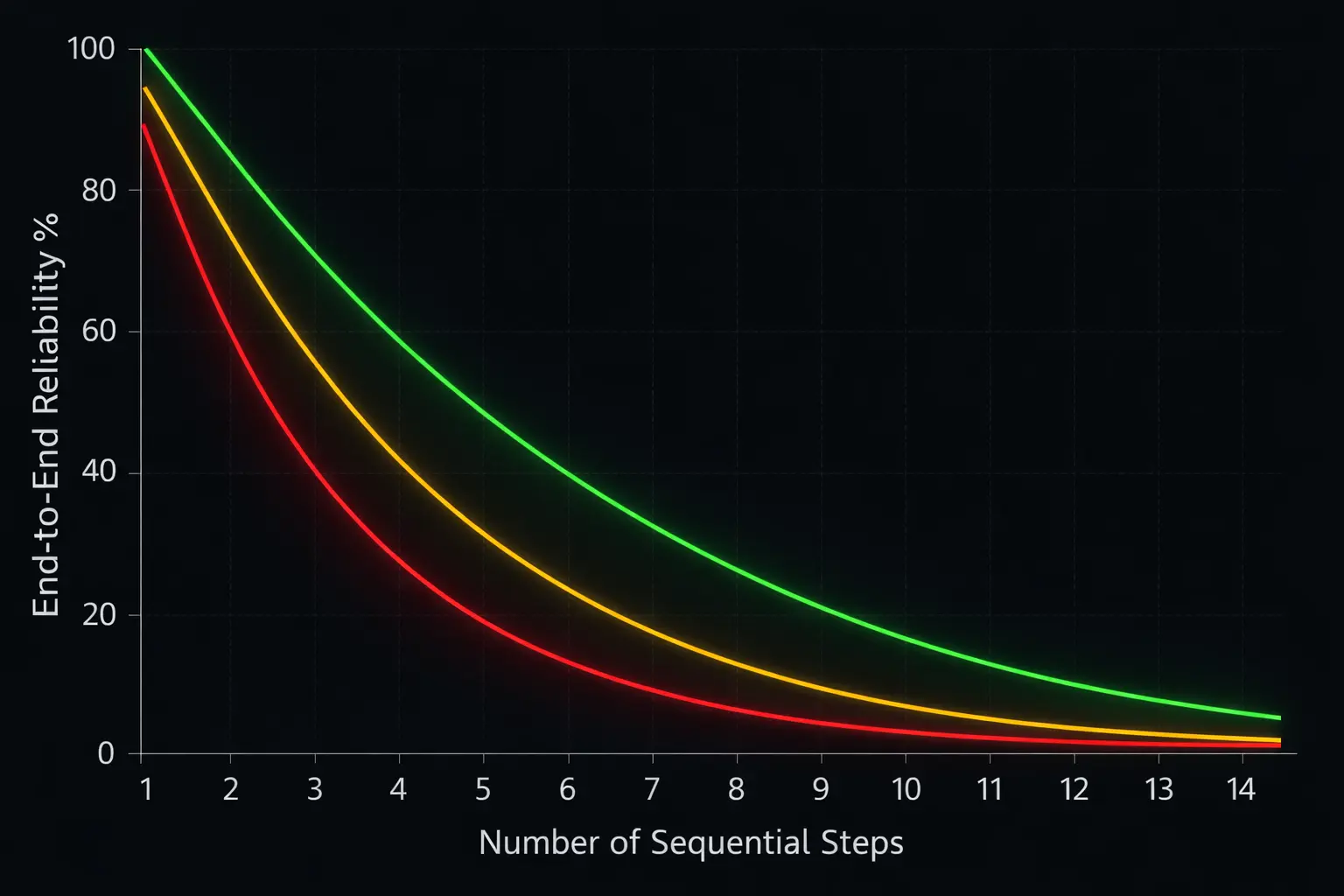
Error compounding is exponential, not linear. If each step in an agent pipeline has 95% accuracy — which is optimistic for tool-heavy workflows — the end-to-end reliability over 10 steps drops to:
0.95¹⁰ ≈ 0.60
A system that's 95% reliable per step is only 60% reliable over a 10-step task. At 90% per step, you're down to 35%. (This, by the way, is the math that demo day conveniently ignores.)
And it's not just a thought experiment. Huang et al. (2023) showed that LLM self-refinement without external verification signals actually degrades output quality — models become confidently wrong rather than cautiously right.
If you've operated an agent in prod, you've seen every one of these:
- Context drift: the agent gradually loses track of the original objective as context windows fill with intermediate state
- Hallucinated tool state: the model fabricates tool return values instead of making actual API calls — like a coworker who confidently reports results from a meeting they never attended
- Error cascading: a subtly wrong Step 3 output becomes the foundation for Steps 4–10, each compounding the error
- Silent failures: the agent reports success on a task it objectively botched, with no signal that anything went wrong
These aren't edge cases. Gartner predicts that over 40% of agentic AI projects will be canceled by the end of 2027, citing escalating costs, unclear business value, and inadequate risk controls. The naive loop is at the center of that.
The Directed Cyclic Graph Pattern
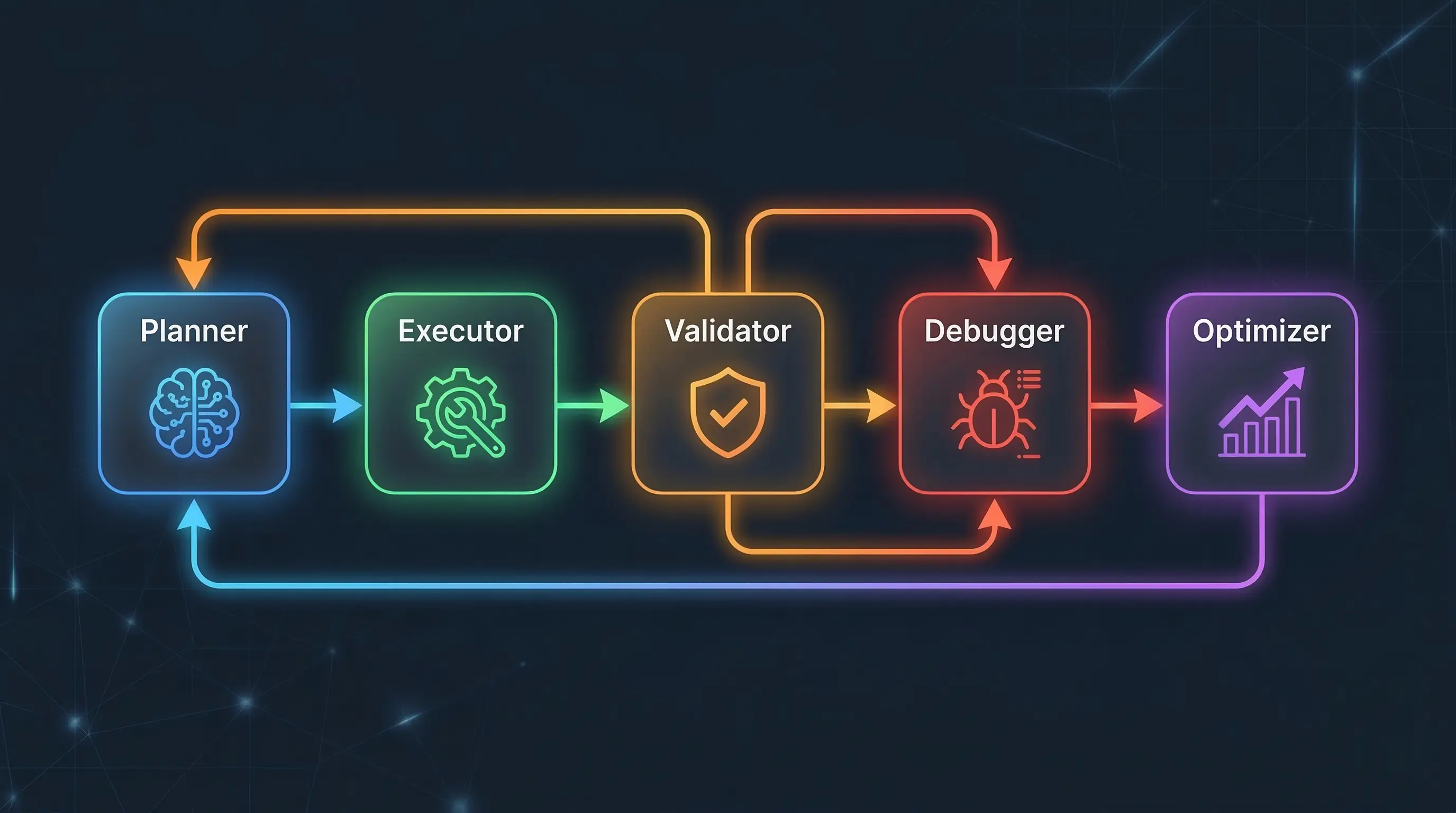
You don't fix this with a better single-model loop. You fix it with a fundamentally different architecture: specialized agents in a directed cyclic graph.
Note the word cyclic. Most agent frameworks talk about DAGs (directed acyclic graphs) — task flows that move in one direction. Production systems need cycles: feedback loops where outputs flow backward through validators and debuggers before moving forward. If your agent graph doesn't have cycles, it can't self-correct, which means you are the debugger.
┌─────────────────────────────────────────────────┐
│ │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │ Planner │───▶│ Executor │───▶│Validator │ │
│ └──────────┘ └──────────┘ └────┬─────┘ │
│ ▲ ▲ │ │
│ │ │ ┌────▼─────┐ │
│ │ │ │ Pass? │ │
│ │ │ └────┬─────┘ │
│ │ │ Yes │ No │
│ │ │ │ │ │
│ │ │ ┌──────┘ │ │
│ │ │ ▼ ▼ │
│ │ │ Output ┌──────────┐ │
│ │ └──────────│ Debugger │ │
│ │ └────┬─────┘ │
│ │ │ │
│ └───────────────────────────────┘ │
│ │
│ ┌──────────┐ │
│ │Optimizer │ (observes all) │
│ └──────────┘ │
└─────────────────────────────────────────────────┘
The cycles are where reliability lives. A validator that can route a failed output back to the debugger, which re-plans and re-executes, turns a 60% reliable pipeline into a 95%+ one. Recursive Introspection (RISE) showed that even open-weight models like Llama and Mistral can iteratively self-improve across multiple turns on math reasoning tasks, outperforming single-turn strategies given equal compute — but only when paired with external verification signals. Without those signals, the model just confidently iterates toward the same wrong answer.
These cycles cost tokens. A lot of tokens. That's the point.
Specialized Agent Roles
Production agentic systems aren't one model wearing many hats. They're ensembles of specialists, each doing one thing well:
Planner — decomposes the user's goal into a structured task graph. Determines sequencing, identifies required tools, anticipates failure points. The architect who never touches a hammer.
Executor — performs the actual work: tool calls, API integrations, code generation, data retrieval. This is the agent most teams build first and mistakenly think is the whole system.
Validator — the most token-hungry role, and the one that earns its keep. Evaluates outputs against explicit criteria: correctness, completeness, safety, consistency with the original intent. The key constraint: validators must be independent of executors — a different model, a different prompt, often a different approach entirely. Multi-Agent Debate (MAD) research shows that independent agents arguing in a structured format significantly outperform self-reflection, which suffers from "Degeneration-of-Thought" — once an LLM locks into an answer, asking it to reconsider is about as productive as asking it nicely.
Debugger — activates when validation fails. Diagnoses why an output was rejected, generates a corrective plan, and routes it back through execution. Without a dedicated debugger, validation failures just trigger blind retries — the system equivalent of turning it off and on again, except it costs you $0.15 each time.
Optimizer — operates at a meta-level. Monitors token spend, latency, and quality metrics across the system. Decides when to cache, when to use a cheaper model, when to short-circuit validation for low-risk tasks. This is the agent that turns the whole thing from a money pit into a business.
How Validation Dominates the Token Budget
Let's trace the actual token flow through a production workflow: a multi-step research agent handling a compliance review across five sequential steps. This is where people's intuitions start to break.
Execution Phase
| Component | Input Tokens | Output Tokens | Subtotal |
|---|---|---|---|
| Planning | 3,000 | 800 | 3,800 |
| Execution (5 steps, growing context) | 18,000 | 5,500 | 23,500 |
| Final synthesis | 4,000 | 1,200 | 5,200 |
| Execution Total | 25,000 | 7,500 | 32,500 |
Validation Phase
| Component | Input Tokens | Output Tokens | Subtotal |
|---|---|---|---|
| Plan validation | 5,000 | 600 | 5,600 |
| Step validation (5 steps × growing context) | 35,000 | 3,000 | 38,000 |
| Output quality check | 10,000 | 800 | 10,800 |
| Safety/compliance check | 8,000 | 600 | 8,600 |
| Consensus voting (2 extra validators on critical steps) | 25,000 | 2,000 | 27,000 |
| Retry/recovery overhead (amortized) | 12,000 | 1,500 | 13,500 |
| Validation Total | 95,000 | 8,500 | 103,500 |
Per-request token ratio: 103,500 / 32,500 ≈ 3.2:1
That's just per-request. At the system level, you're also burning tokens on:
- Evaluation harnesses that run hundreds of test cases on every model update or prompt change
- Shadow mode testing that duplicates production traffic through new agent versions, comparing outputs
- Quality monitoring that samples live requests for deep analysis
- Regression suites that verify past failure cases haven't resurfaced
Add it all up — per-request validation, evaluation pipelines, shadow testing, monitoring — and the ratio pushes toward 8:1 to 10:1 in mature deployments. In regulated industries (finance, healthcare, legal), where a wrong output can trigger compliance violations or worse, ratios above 10:1 are normal. Nobody blinks.
Why This Is Rational
The economics aren't subtle. Consider:
Wrong output cost: $50–$500 per incident (customer escalation, reputational damage, regulatory penalty, manual rework).
Validation cost: $0.01–$0.05 in additional tokens per request.
If validation reduces your failure rate from 35% to 3%, the expected savings per request is:
(0.35 − 0.03) × $200 = $64.00 saved per request
You'd be irrational not to spend $0.05 to save $64. The 10:1 token ratio isn't wasteful — it's where the cost curve bottoms out for systems where mistakes have real consequences.
Cost Modeling for Validation-Heavy Architectures
The insight that makes this affordable is model tiering. You don't validate with a frontier model — you validate with a reliable judge.
Here's what that looks like with current API pricing (as of March 2026):
Architecture A: Naive Loop (Frontier Model, No Validation)
| Tokens | Model | Cost | |
|---|---|---|---|
| All execution | 32,500 | Frontier ($3/$15 per 1M) | $0.19 |
| Retries (40% failure rate) | 13,000 | Frontier | $0.08 |
| Human escalation (10% of requests) | — | — | $0.20 |
| Total effective cost | 45,500 | $0.47/request |
Architecture B: Validation-Heavy (Tiered Models)
| Tokens | Model | Cost | |
|---|---|---|---|
| Execution | 32,500 | Frontier ($3/$15 per 1M) | $0.19 |
| Validation | 103,500 | Mid-range ($0.80/$4 per 1M) | $0.10 |
| Retries (5% failure rate) | 6,800 | Mixed | $0.03 |
| Total effective cost | 142,800 | $0.32/request |
Architecture B burns 3x more tokens but costs 32% less per request. At 10,000 requests per day:
- Architecture A: $4,700/day ($141K/month)
- Architecture B: $3,200/day ($96K/month)
Saving: $45K/month — by spending more tokens on validation.
And you can push this further. Use a mid-range model (like Claude Haiku 3.5 at $0.80/$4.00 per 1M tokens) for nuanced validation, a cheap one (like GPT-4.1 nano at $0.20/$0.80) for format checks, and suddenly that $0.10 validation line item gets halved. The token count goes up, the bill goes down. It's the only budget line I've seen where spending more is the responsible choice.
When to Invest in Cheaper Validator Models
If validators eat most of the tokens, the obvious next question is: can we make them cheaper?
Yes. And the answer is more encouraging than you'd expect.
The Semantic Capacity Asymmetry Hypothesis
A study on Semantic Capacity Asymmetry proposed something practitioners have long suspected: evaluation requires significantly less semantic capacity than generation. Checking whether an answer is correct is fundamentally easier than producing it from scratch. (Your English teacher could spot bad grammar without being a novelist. Same principle.)
The data backs this up:
- Flow Judge, a 3.8-billion-parameter open-source model built on Phi-3.5-mini, achieves an F1 score of 0.96 on evaluation benchmarks — comparable to GPT-4o (0.99) at a fraction of the size and cost.
- TIR-Judge, an 8B model using tool-integrated reasoning with a code executor, achieves listwise evaluation performance comparable to frontier-class models like Claude Opus.
- Multi-Agent Reflexion (MAR) showed that separating critique into diverse persona-guided critics and a synthesizing judge achieves a 6+ point improvement on HumanEval over single-agent Reflexion — without any fine-tuning.
The practical upshot: run your executor on a frontier model for maximum capability, and your validators on something 10–50x cheaper per token. The quality loss is minimal. The cost savings are not.
A Practical Tiering Strategy
┌────────────────────────────────────────────────────┐
│ TIER 1: FRONTIER MODEL (execution + hard judgment) │
│ Use: Planning, complex tool orchestration, │
│ ambiguous edge-case validation │
│ Cost: $3–$15 per 1M tokens │
├────────────────────────────────────────────────────┤
│ TIER 2: MID-RANGE MODEL (standard validation) │
│ Use: Output quality checks, consistency validation,│
│ safety screening │
│ Cost: $0.80–$4 per 1M tokens │
├────────────────────────────────────────────────────┤
│ TIER 3: EFFICIENT MODEL (high-volume validation) │
│ Use: Format checks, schema validation, simple │
│ pass/fail classification, step-level checks │
│ Cost: $0.20–$0.80 per 1M tokens │
├────────────────────────────────────────────────────┤
│ TIER 4: DETERMINISTIC CHECKS (zero LLM cost) │
│ Use: JSON schema validation, regex patterns, type │
│ checking, API response code verification │
│ Cost: $0 │
└────────────────────────────────────────────────────┘
The optimizer agent decides which tier handles each check. A format validation doesn't need GPT-5 — a regex will do. A nuanced quality judgment might need a mid-range model. Only genuinely ambiguous edge cases warrant frontier-model validation. (I once watched a team route JSON schema checks through Claude Opus. Their bill was impressive. Their architecture was not.)
In practice, this tiering pushes 60–70% of validation tokens to Tier 3 or Tier 4, cutting validation costs by an order of magnitude while preserving reliability.
Build the Skeptic, Not Just the Worker
The instinct when building an AI agent is to make it capable. More tools, bigger context window, longer chain-of-thought. Make it do more.
Production teaches the opposite. The most important agent in your system is the one that says no. The validator. The skeptic. The one that reads every output with the energy of a code reviewer on a Friday afternoon and asks: "Are you sure? Prove it."
This means the majority of your token budget — your primary operating cost — produces nothing visible. No outputs, no deliverables, no user-facing work. Just judgment.
That's why it works. In software engineering, we accepted decades ago that testing consumes more effort than writing code. In agentic AI, we're learning the same lesson with a different currency: verification is more expensive than generation, and that's exactly where the money should go.
Budget accordingly.
The cost models in this article use published API pricing as of March 2026 from OpenAI and Anthropic. Actual costs vary by provider, volume tier, and caching strategy. The 10:1 ratio is an observed heuristic in high-reliability production deployments, not a universal constant — your ratio will depend on your reliability requirements and the cost of failures in your domain.