The LLM Gateway Pattern: Building the Control Plane Your AI Platform Is Missing
Most enterprises call LLMs directly from application code—creating integration sprawl, zero cost visibility, and no ability to swap models. The LLM Gateway pattern fixes all of it.
Enterprise LLM spending hit $8.4 billion in the first half of 2025—more than double all of 2024. Token prices dropped over 200x in two years. And yet, somehow, AI bills at most companies tripled.
The math isn't broken. The architecture is.
What happened is straightforward: when calling an LLM is as easy as requests.post(), every team does it. Marketing has a Claude integration. Engineering has three OpenAI keys. Customer support is running Gemini through a contractor's personal account. Nobody knows what anything costs, nobody can swap providers without a code freeze, and the CISO is having a very bad quarter.
I've watched this play out across enough organizations to recognize a pattern—and, more usefully, to recognize the architectural fix. It's the same fix the industry landed on for REST APIs fifteen years ago: put a gateway in front of everything.
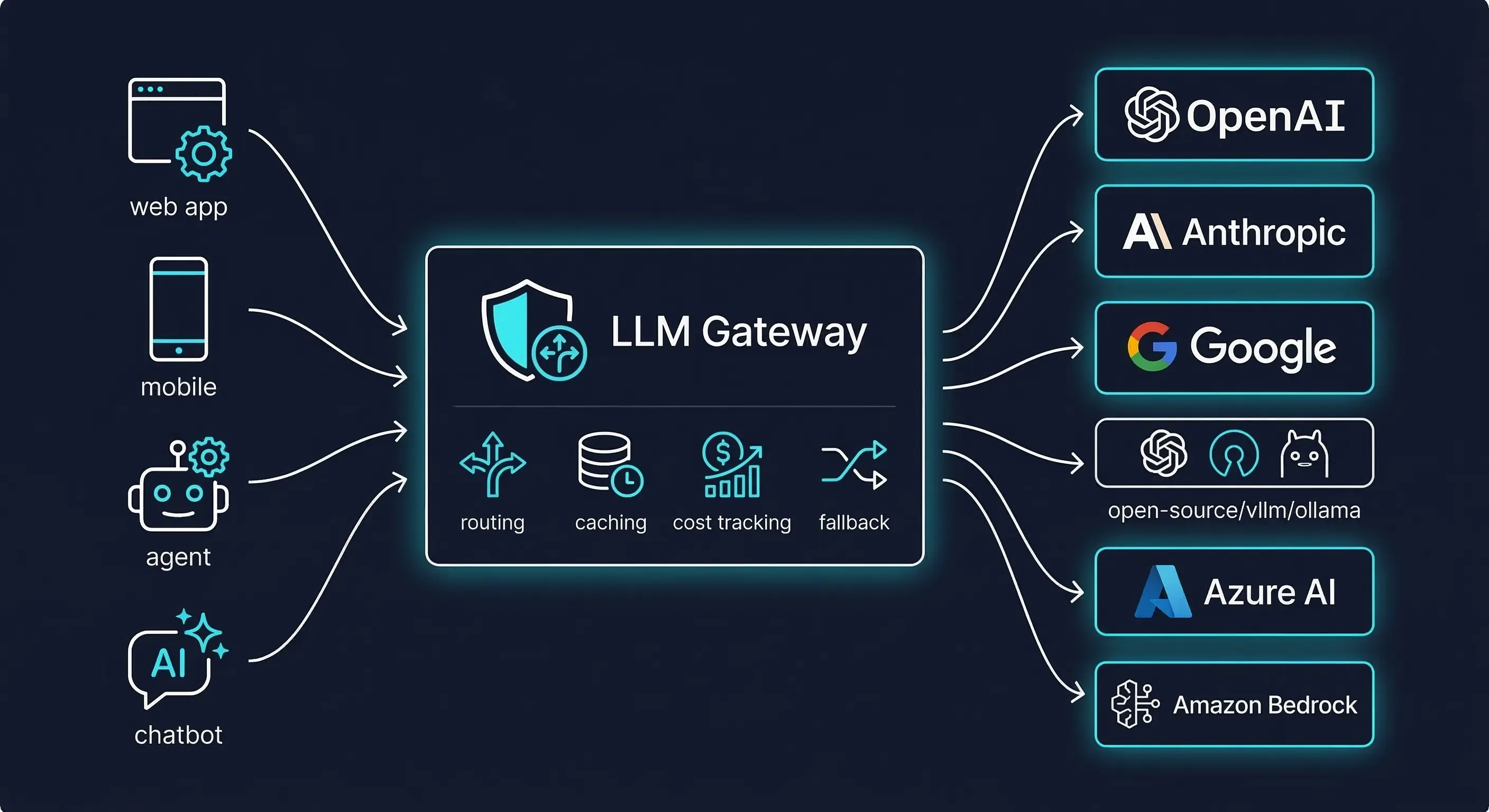
The Integration Sprawl Problem
Here's what "calling LLMs directly" looks like at a company with twenty engineering teams:
- 20+ sets of API keys scattered across environment variables, secrets managers, and that one Notion doc from the hackathon
- Zero aggregate cost visibility—each team's usage is buried in separate cloud billing dashboards that nobody reconciles
- Provider lock-in everywhere—switching from OpenAI to Anthropic means touching every service that makes an LLM call
- No fallback logic—when OpenAI has an outage (and they do), every downstream service fails simultaneously
- Inconsistent retry behavior—some services retry on 429s, some don't, some retry on 500s with no backoff and make the rate-limiting worse
If this sounds familiar, congratulations: you've independently discovered why API gateways exist.
A Decade-Old Pattern, Reimagined
The API gateway emerged in the early 2010s when microservices architectures created exactly this problem for REST APIs. Instead of every service managing its own authentication, rate limiting, and circuit breaking, you put a single layer in front—Kong, Apigee, AWS API Gateway—and centralized the cross-cutting concerns.
The LLM Gateway is the same architectural insight applied to model inference. But it's not a copy-paste. LLM traffic has properties that REST API gateways never had to handle:
| Concern | REST API Gateway | LLM Gateway |
|---|---|---|
| Billing unit | Requests | Tokens (input + output, priced differently) |
| Caching | Exact URL + params match | Semantic similarity matching |
| Rate limiting | Requests per second | Tokens per minute + requests per minute |
| Routing | Path-based, header-based | Model capability, cost, latency, task complexity |
| Response format | Complete JSON body | Often streamed (SSE), variable length |
| Security | SQL injection, XSS | Prompt injection, data exfiltration, PII leakage |
| Failover | Any instance of same service | Different model, different provider, different capability |
The billing difference alone makes LLM gateways fundamentally more complex. A single API call might cost $0.0001 or $0.50 depending on the model, the input length, and the output length—and you don't know the output cost until the response finishes streaming. Try doing that cost attribution with an nginx reverse proxy.
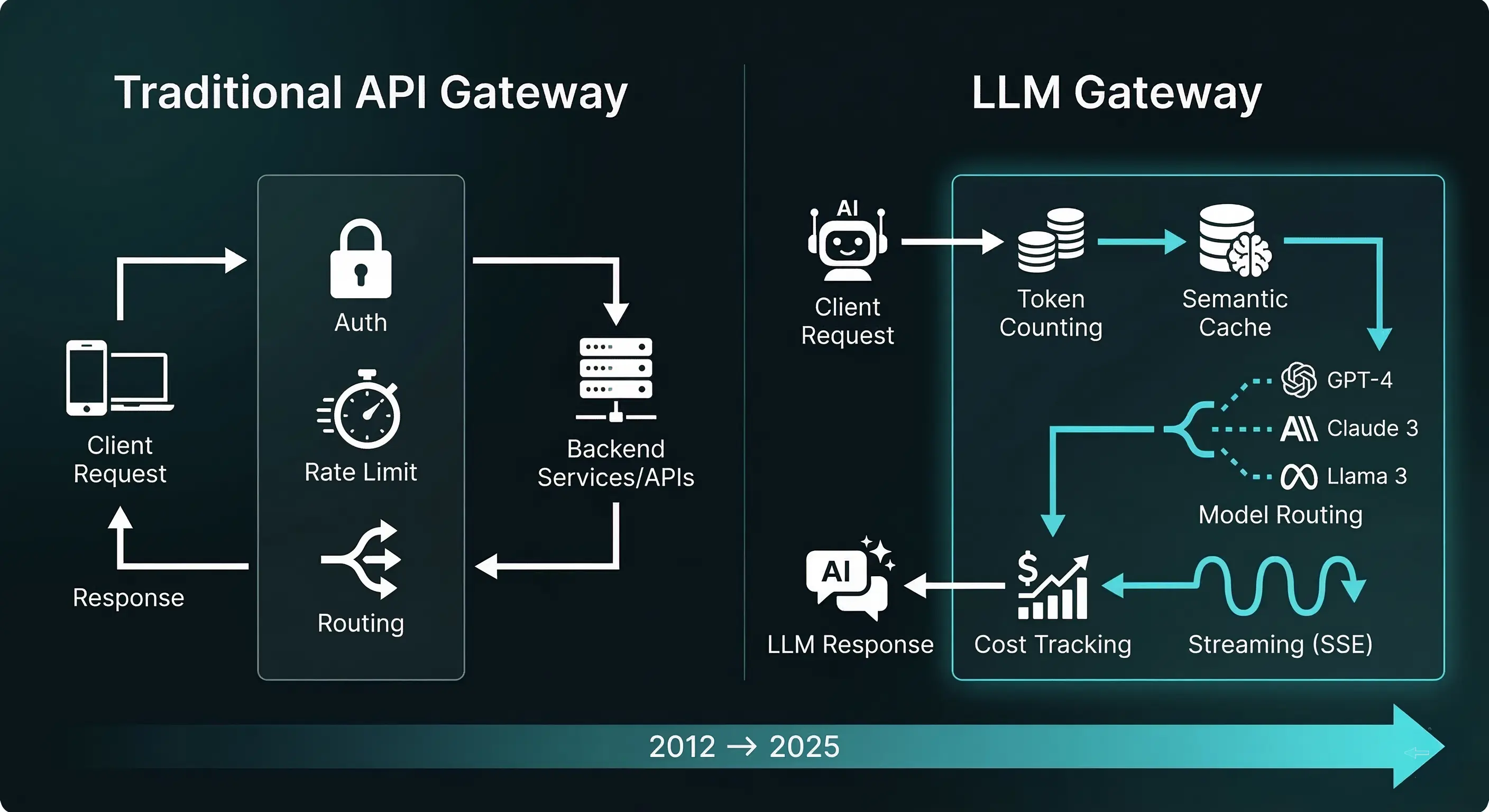
Anatomy of an LLM Gateway
A production LLM Gateway sits between your application layer and the model providers. Its job is deceptively simple: accept an inference request in a standard format, figure out where to send it, handle the response, and report what happened. The complexity lives in the "figure out where to send it" part.
Here's the core component stack:
┌─────────────────────────────────────────────────────────┐
│ Application Layer │
│ (APIs, Agents, Chatbots, Internal Tools, Batch Jobs) │
└──────────────────────┬──────────────────────────────────┘
│ OpenAI-compatible API format
▼
┌────────────────────────────────────────────────────────┐
│ LLM GATEWAY │
│ ┌───────────┐ ┌──────────┐ ┌────────────────────┐ │
│ │ Auth & │ │ Semantic │ │ Request Router │ │
│ │ Keys │ │ Cache │ │ (model selection, │ │
│ │ │ │ │ │ load balancing) │ │
│ └───────────┘ └──────────┘ └────────────────────┘ │
│ ┌───────────┐ ┌──────────┐ ┌────────────────────┐ │
│ │ Cost │ │ Fallback │ │ Rate Limiting │ │
│ │ Tracker │ │ & Retry │ │ (per-key, per- │ │
│ │ │ │ │ │ team, per-model) │ │
│ └───────────┘ └──────────┘ └────────────────────┘ │
│ ┌──────────────────────────────────────────────────┐ │
│ │ Observability & Logging │ │
│ │ (latency, tokens, cost, errors, per-request) │ │
│ └──────────────────────────────────────────────────┘ │
└──────────────────────┬─────────────────────────────────┘
│
┌────────────┼────────────┐
▼ ▼ ▼
┌──────────┐ ┌──────────┐ ┌──────────┐
│ OpenAI │ │Anthropic │ │ Google │ ...
└──────────┘ └──────────┘ └──────────┘
The key insight: every application talks to the gateway using one API format (typically OpenAI's chat completions format, which has become the de facto standard). The gateway handles the translation to each provider's API. Your application code never imports anthropic or google.generativeai. It imports nothing—it makes an HTTP call to an internal endpoint.
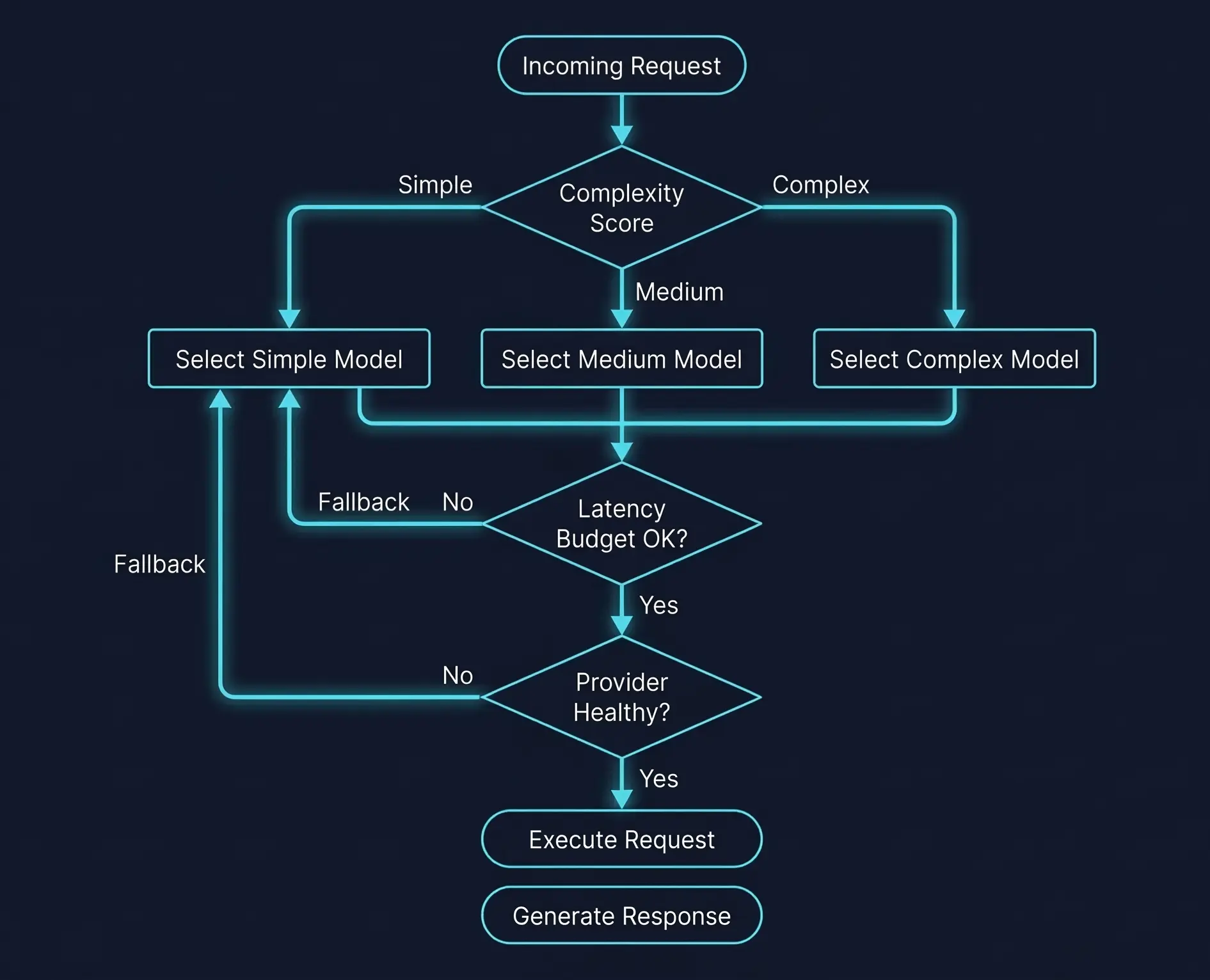
Intelligent Routing: Beyond Round-Robin
The simplest routing strategy is a model alias: your app requests gpt-4-equivalent, and the gateway maps it to whatever model you've configured this week. That alone is worth the setup cost—it decouples deployment from model selection.
But the real leverage comes from complexity-aware routing. Not every request needs a frontier model. A recent survey on dynamic model routing and cascading shows that intelligent routing reduces inference costs by 40–85% while maintaining 90–95% of quality.
The approach I've seen work best in practice uses three tiers:
| Task Complexity | Example Tasks | Model Tier | Typical Cost (per 1M tokens) |
|---|---|---|---|
| Simple | Classification, formatting, extraction | GPT-4.1 nano, Claude Haiku 3.5 | $0.10–$0.80 input |
| Standard | Summarization, Q&A, basic analysis | GPT-4.1 mini, Claude Haiku 4.5 | $0.40–$1.00 input |
| Complex | Multi-step reasoning, code generation | Claude Sonnet 4.6, GPT-4.1 | $2.00–$3.00 input |
You can implement the classifier as a lightweight model call (a nano/flash model classifying the incoming prompt), embedding-based similarity against labeled examples, or even rule-based heuristics on prompt length and keyword presence. The classifier itself costs fractions of a cent per call—the savings on routing 70% of traffic to cheaper models pay for it thousands of times over.
The latency dimension matters too. I've measured GPT-4.1 mini's time-to-first-token at roughly 9% slower than GPT-4o mini for equivalent tasks, but with meaningfully better output quality on structured extraction. Whether that tradeoff makes sense depends on your P95 latency budget—which is exactly the kind of decision a gateway can make dynamically, per-request, based on current provider latency.
Semantic Caching: The 10x You Didn't Know You Had
Traditional API caching is trivial: same URL, same params, same response. LLM caching is harder because semantically identical prompts are rarely textually identical. "Summarize this document" and "Give me a summary of the attached doc" should hit the same cache. Exact string matching misses these entirely.
Semantic caching solves this by embedding incoming prompts into vector space and finding nearest neighbors above a similarity threshold. If a cached response exists within, say, cosine similarity 0.95 of the new request, return it without calling the model.
The architecture, pioneered by projects like GPTCache, chains four components:
- Embedding model — converts the prompt to a vector (a small, fast model like
text-embedding-3-small) - Vector store — indexes and searches cached embeddings (Redis, Qdrant, Weaviate, Pinecone)
- Similarity evaluator — decides if the nearest cache hit is "close enough" (cosine similarity with configurable threshold)
- Cache manager — handles TTL, eviction, and invalidation
In document-heavy enterprise workflows—think "answer questions about this policy document" or "extract clauses from this contract"—cache hit rates can be surprisingly high. Multiple users asking variations of the same question about the same document will share cached responses. I've seen effective hit rates of 30–60% in document Q&A workloads, which translates directly to 30–60% cost reduction on those endpoints.
The gotcha: similarity threshold tuning is everything. Set it too loose (0.85) and you'll serve wrong answers for subtly different questions. Set it too tight (0.99) and you get almost no cache hits. Start at 0.95, measure answer quality on a held-out test set, and adjust. There's no universal right answer—it depends on how sensitive your use case is to variation in responses.
More advanced approaches are emerging: vCache uses hierarchical matching across different semantic levels, and GenerativeCache can synthesize new responses from multiple cached fragments. But for most production deployments, vanilla vector-similarity caching with a good embedding model gets you 80% of the benefit.
Fallback Policies: When (Not If) Providers Go Down
Every LLM provider has outages. OpenAI's status page reads like a war diary. Anthropic rate-limits aggressively during peak hours. Google's API occasionally returns errors that aren't documented anywhere. If your application calls one provider and that provider is down, your application is down.
A gateway turns this from a catastrophic failure into a routing decision. The pattern layers three mechanisms:
Retries handle transient errors—HTTP 429 (rate limited) and 5xx (server error). The implementation that actually works in production:
retry_config = {
"retryable_status_codes": [429, 500, 502, 503, 504],
"max_retries": 3,
"backoff": "exponential", # 1s, 2s, 4s
"jitter": True, # ±20% randomization
"non_retryable": [400, 401, 403, 404] # don't retry bad requests
}
The jitter is non-negotiable. Without it, a thousand clients that all hit a 429 at the same second will all retry at the same second, creating a thundering herd that makes the rate-limiting worse.
Fallbacks activate when retries are exhausted or the error is non-transient. The gateway routes to an alternative model or provider:
Primary: gpt-4.1 → (failed after 3 retries)
Fallback 1: claude-sonnet-4.6 → (try Anthropic)
Fallback 2: gemini-2.5-pro → (try Google)
Fallback 3: gpt-4.1-mini → (downgrade model tier)
Note the last fallback: sometimes a degraded response from a smaller model is better than no response at all. A chatbot that returns a slightly less nuanced answer is infinitely better than a chatbot that returns a 500 error.
Circuit breakers prevent cascade failures by proactively stopping requests to an unhealthy provider. If OpenAI returns errors on 50% of requests in a 60-second window, the circuit "opens" and all traffic routes to fallbacks for a cooldown period. After the cooldown, a few probe requests test if the provider has recovered.
CLOSED (normal) → error rate > threshold → OPEN (blocking)
│
cooldown timer
│
▼
HALF-OPEN (probing)
│ │
success failure
│ │
▼ ▼
CLOSED OPEN
The three patterns layer: retries handle blips, fallbacks handle provider-level failures, circuit breakers prevent your retry logic from hammering an already-struggling service. Without all three, you're one OpenAI incident away from a P1.
Token-Level Cost Attribution: Where the Money Actually Goes
Here's a conversation I've had at least a dozen times:
"How much are we spending on AI?" "About $140K a month." "Okay, which teams? Which products? Which use cases?" "...we'll get back to you."
The fundamental problem: LLM costs are metered in tokens, but business decisions are made in dollars-per-team, dollars-per-product, and dollars-per-customer. Bridging that gap requires attribution at the request level.
A well-instrumented gateway tags every request with metadata:
{
"request_id": "req_a8f3c2d1",
"team": "customer-support",
"product": "help-center-bot",
"environment": "production",
"model": "gpt-4.1-mini",
"input_tokens": 1847,
"output_tokens": 423,
"cost_usd": 0.001416,
"latency_ms": 1230,
"cache_hit": false,
"timestamp": "2026-03-15T14:22:07Z"
}
With this data flowing into your analytics pipeline, you can answer every question finance will ever ask:
- Cost per team per month — enable chargeback or showback models
- Cost per conversation — understand unit economics of AI features
- Cost per model — identify which models are being over/under-used
- Cache savings — quantify the ROI of your semantic cache
- Latency by provider — data-driven routing decisions
LiteLLM's proxy, for example, supports custom metadata tags on every request and can enforce per-team and per-key budget limits. When the customer support team's $15K monthly budget is 80% consumed, the gateway can alert, throttle, or automatically downgrade to cheaper models—before anyone gets a surprise invoice.
Building This on Open Source (Without Vendor Lock-In)
You don't need to build an LLM Gateway from scratch. Two open-source projects cover most of the functionality:
LiteLLM is a Python-based proxy that supports 100+ LLM providers through a unified OpenAI-compatible API. Its strengths are breadth of provider support, built-in cost tracking, multi-tenant key management (organizations → teams → users → virtual keys), and configurable routing strategies (least-busy, latency-based, cost-based, usage-based). For most teams, LiteLLM-in-a-Docker-container is the 80/20 solution.
Bifrost is a Go-based alternative focused on raw performance. In benchmarks, Bifrost achieves sub-millisecond P99 gateway overhead compared to LiteLLM's higher latency under load—a consequence of Go's goroutine-based concurrency versus Python's GIL. If you're processing thousands of concurrent requests and gateway latency matters, Bifrost is worth evaluating.
A pragmatic architecture uses both:
High-throughput, latency-sensitive paths → Bifrost
│
Everything else (multi-tenant, cost │
tracking, complex routing) → LiteLLM Proxy
│
Shared config, shared observability
The implementation path I'd recommend:
- Week 1: Deploy LiteLLM proxy with a single model, pointed at by one application. Validate that the OpenAI-compatible API works as a drop-in replacement.
- Week 2: Add a second provider as a fallback. Implement basic retry logic. Add request metadata tagging.
- Week 3: Enable cost tracking. Set up per-team virtual keys. Build a dashboard.
- Week 4: Add semantic caching for your highest-volume endpoint. Measure cache hit rates and cost savings.
- Month 2+: Introduce complexity-based routing. Evaluate Bifrost for performance-critical paths. Add circuit breakers.
The beauty of the gateway pattern is that it's incrementally adoptable. You don't need to migrate every service at once. Start with one team, one application, one model—then expand.
What This Unlocks (Beyond the Obvious)
Once the gateway is in place, capabilities start compounding:
Model A/B testing becomes trivial. Want to compare Claude Sonnet 4.6 against GPT-4.1 on your summarization pipeline? Route 10% of traffic to each, compare quality and cost, make a data-driven decision. No code changes required.
Compliance and audit trails happen automatically. Every prompt and response flows through one place. PII detection, content filtering, and prompt injection scanning can be applied uniformly instead of reimplemented in every service.
Model upgrades are zero-downtime. When OpenAI releases GPT-5, you update the gateway config. Every application gets the new model simultaneously, with the old model as a fallback if the new one regresses.
Cost anomaly detection becomes possible. A sudden spike in token usage from one team? The gateway notices before the monthly invoice arrives.
The Pattern That Keeps Repeating
Every major infrastructure shift follows the same arc: teams build point-to-point integrations, integration sprawl becomes unmanageable, someone puts a unified layer in the middle, and everyone wonders why they didn't do it sooner. Load balancers. API gateways. Service meshes. Container orchestrators.
LLM Gateways are the same pattern at a different layer of the stack. The enterprises that build this now—while they have dozens of LLM integrations—will be glad they did when they have hundreds. The ones that wait will eventually build it anyway, just with more technical debt to unwind.
The control plane your AI platform is missing isn't a product you buy. It's an architectural decision you make. Preferably before the next surprise invoice.